NLP

자연어 처리는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나다. 자연어 처리는 연구 대상이 언어이기 때문에 당연하게도 언어 자체를 연구하는 언어학과 언어 현상의 내적 기재를 탐구하는 언어 인지 과학과 연관이 깊다. 구현을 위해 수학적 통계적 도구를 많이 활용하며 특히 기계학습 도구를 많이 사용하는 대표적인 분야이다. 정보검색, QA 시스템, 문서 자동 분류, 신문기사 클러스터링, 대화형 Agent 등 다양한 응용이 이루어지고 있다.
따라서 텍스트를 정제하는 전처리 과정이 반드시 필요하다.
원리 이해하기
텍스트 데이터를 신경망에 입력하기 위해서 일반적으로 토큰화 작업을 수행하고 정의된 토큰에 고유 인덱스를 부여한 뒤, 인코딩을 통해 적절한 형태로 바꿔주는 전처리 작업 과정을 거치게 된다.
1) 토큰화
먼저 해야 할 일은 텍스트를 잘게 나누는 것이다. 텍스트를 단어별, 문장별, 형태소별로 나눌 수 있는데 문법적으로 더 이상 나눌 수 없는 언어 요소를 토큰이라 한다. 그리고 이를 수행하는 작업을 토큰화라고 한다. 특히 Korean은 교착어이기 때문에 형태소별로 나누어야 모델 학습에 수월하다. 또한 어휘의 크기를 줄여 메모리를 확보해야 하기에 토큰화가 필요하다.

이렇게 주어진 텍스트를 단어 단위로 쪼개고 나면 이를 이용해 여러 가지를 할 수 있다.
예를 들어 다음과 같은 세 개의 문장이 있다고 하자.
먼저 텍스트의 각 단어를 나누어 토큰화합니다.
텍스트의 단어를 토큰화해야 딥러닝에서 인식됩니다.
토큰화 한 결과는 딥러닝에서 사용할 수 있습니다.
위의 세 문장에 등장하는 단어를 모두 세어 보고 출현 빈도가 가장 높은 것부터 나열해 보면, '토큰화'가 3회, '딥러닝에서'가 2회, '텍스트의'가 2회, 그리고 나머지 단어들이 1회씩이다. 가장 많이 사용된 단어인 '토큰화, 딥러닝, 텍스트'가 위 세 문장에서 중요한 역할을 하는 단어임을 짐작할 수 있다.
다음과 같이 케라스의 Tokenizer() 함수를 사용하면 단어의 빈도 수를 쉽게 계산할 수 있다.
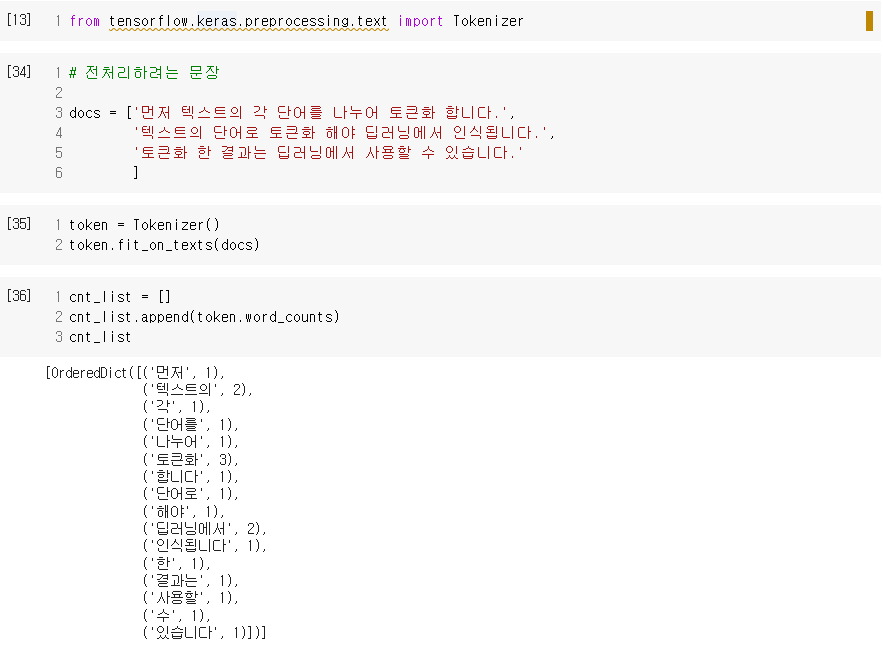

- 각 단어에 매겨진 인덱스 값은 word_index 함수로 알 수 있다.
2) 원-핫 인코딩
토큰화를 통해 단어를 분류해 줬다면, 단어가 문장의 다른 요소와 어떤 관계를 가지고 있는지에 대한 정보 등을 알아보는 방법이 필요하다. 이러한 기법 중에서 대표적으로 원-핫 인코딩, 이진 인코딩이 있으며, 텍스트 데이터를 사용하는 경우엔 기본적으로 Embedding층을 사용한다. 이를 워드 임베딩이라 표현하는데 이는 뒤에서 다시 설명한다.
원-핫 인코딩은 각 단어를 모두 0으로 바꾸어 주고 원하는 단어만 1로 바꾸어 주는 것이다. 이를 수행하기 위해 먼저 단어 수만큼 0으로 채워진 벡터 공간으로 바꾼다. 각 단어가 배열 내에서 해당하는 위치를 1로 바꿔서 다음과 같이 벡터화할 수 있다.

파이썬 배열의 인덱스가 0부터 시작하므로, 맨 앞에 0이 추가되는 것에 주의하자. 즉, 배열 맨 앞에 0이 추가되므로 단어 수보다 1이 더 많게 인덱스 숫자를 잡아 주면 된다.
단어 임베딩
원-핫 인코딩을 그대로 사용하면 벡터의 길이가 너무 길어진다는 단점이 있다. 예를 들어 1만 개의 단어 토큰으로 이러어진 데이터를 다룬다고 할 때, 이 데이터를 원-핫 인코딩으로 벡터화하면 9,999개의 0과 하나의 1로 이루어진 단어 벡터를 1만 개나 만들어야 한다. 이러한 공간적 낭비를 해결하기 위해 등장한 것이 단어 임베딩(word embedding)이라는 방법이다.
단어 임베딩은 주어진 배열을 정해진 길이로 압축시킨다. 이러한 과정과 결과가 가능한 이유는 각 단어 간의 유사도를 계산했기 때문이다.

그렇다면 이 단어 간 유사도는 어떻게 계산할까? 적절한 크기로 배열을 바꾸어 주기 위해 최적의 유사도를 계산하는 학습 과정을 역전파를 통해 학습한다. 이는 케라스에서 제공하는 embedding() 함수를 사용하여 간단히 해낼 수 있다.
from keras.layers import Embedding
model = Sequential()
# Embedding 함수는 최소 2개의 매개변수를 필요로 하는데, 바로 '입력'과 '출력'의 크기이다.
model.add(embedding(16,4))
# 16개의 단어를 입력, 임베딩 후 출력되는 벡터 크기는 4로 하겠다는 의미이다.
# embedding(16,4, input_length=2) 라고 하면 총 입력되는 단어 수는 16개지만 매번 2개씩만 넣겠다는 의미.